Где-то около года назад я затеял пилить небольшой коммерческий продукт с говорящим названием Зада4кин.
Суть в двух словах: скидываешь ему фото задачки (математической, логической, литературной и т.п.) и он тебе выдаёт ответ.

Тогда я ещё не был знаком с библиотеками по распознаванию русского текста, поэтому пришлось набивать шишки в буквальном смысле.
Поэтому ниже мой опыт реализации Зада4кин’а.
Выбор OCR-инструмента
Первое, чем надо заняться, - это выбрать OCR-инструмент. Короче говоря это нейросеть, которая умеет хорошо понимать русские тексты на фотографии. А желательно еще, чтобы она была бесплатная. Звучит, конечно, как утопия, но несколько решений всё-таки были на рынке (мой опыт датируется октябрём 2025 года)
-
EasyOCR через OpenCV на самых маленьких настройках (т.к. тестирую на cpu) хоть и работал, но давал плохой результат если это не скан с чётким расположением документа (без наклонов, засветов). Он начинал как будто бы путать буквы или перемешивать. В общем я не стал разбираться и просто пошел дальше.
-
Tesseract OCR и TrOCR. Tesseract русский язык поддерживает, но в моих тестах на фото задачек с наклонами/засветами результат был слабый. А TrOCR из коробки под мой кейс с русским текстом не подошёл, хотя существуют отдельные дообученные модели под кириллицу.
-
PaddleOCR. Китайский PP-OCRv5 ванлав, потому что есть модели под кириллицу/восточнославянские языки, и относительно из коробки он работает с очень плохими изображениями.
Например даже с такими фото из коробки не было проблем

Но всё равно для чего-то более сложного надо было писать свой кастомный препроцессор.
Препроцессор: что это и зачем
Перед тем, как подать нашу фотку в модель мы можем в ней немного увеличить яркость, контраст, повернуть ее, убрать искажение, если оно есть. Это все равно что вы редактируете фото на своем iPhone когда только что сфоткали, через ползунки и настройки. Вот эти ползунки и настройки и должны стать препроцессором для фотографий. Только работать это должно в автоматическом режиме, ведь оператора не будет.
Да, сейчас я понимаю, что для MVP качества PaddleOCR хватило бы из коробки, но тогда пайплайн без предобработки фото казался чем-то костыльным и слабым. И я приступил к реализации препроцессора.
Что конкретно делал с фоткой
- Исправление EXIF-ориентации (EXIF-ориентация - это метаданные внутри JPEG-файлов, указывающие положение камеры (горизонтальное/вертикальное) при съёмке с помощью встроенного акселерометра)
- Определение типа изображения: фото или скриншот (скриншот определяется по размеру, активности границ через Canny и резкости через дисперсию Лапласиана). Просто со скриншотами легче работать.
- Перевод в grayscale (было цветное, стало серое - так проще и стабильнее для моего пайплайна)
- Оценка наклона текста и потом выравнивание наклона - Deskew (если угол в диапазоне примерно 3–20°, изображение поворачивается обратно без обрезки углов)
- Шумоподавление (Шумодав включается только при проблемах: блики, мягкое/размытое изображение, тёмный низкоконтрастный кадр)
- Soft upscale + unsharp (если резкость совсем низкая, картинка увеличивается до 1.5x, потом слегка шарпится (увеличивается резкость))
- CLAHE для локального усиления контраста (это алгоритм улучшения изображений, который усиливает локальный контраст, не допуская при этом чрезмерного шума)
Это не полный препроцессор, внутри были еще некоторые мелкие нюансы, но в целом это основа.
Зачем всё это
Ну вот вы спросите: “а зачем вообще такие траблы чтобы считать текст с фото?”
Т.к. ничто не является истиной мы проводим А\В тесты изображений чтобы понять какие мы можем “читать”, а какие нет и нам нужно улучшать их качество.

Да, изображения такого качества я создал специально чтобы протестировать работу сервиса.
И да, он распознал текст на фото.
Немного теории: как работает OCR
Но чтобы это не было магией, немного теории как работают нейросети распознавания текста на фото:
OCR-модель вроде той, которую я использовал, PaddleOCR - это не одна нейросеть, которая читает картинку целиком. Обычно это похоже на конвейер.
Сначала изображение попадает в детектор текста. Тут нам надо найти на картинке области, где вообще есть текст: строки, слова, блоки, табличные фрагменты. На выходе отдаем координаты боксов или полигонов вокруг текста. Мы не распознаем все вообще, мы распознаем те места, где есть текст.
Затем каждый найденный фрагмент передаётся в модель распознавания текста. Она уже не ищет текст, а читает конкретную вырезанную область и превращает изображение строки в символы. Условно: на вход ей приходит маленькая картинка со строкой, на выходе получается “Здравствуй Ваня седня баня” и confidence score (это что-то типа оценки, насколько модель уверена в распознанной строке).
Да, в PP-OCR уже в коробке есть свой препроцессор для плохих фоток: определение ориентации документа, выравнивание страницы, исправление поворота строк и т.п. но опять же мы опираемся на А/В тесты изображений, поэтому пишем свой.
Таким образом мы приводим изображение в более удобный вид для детектора и распознавателя.
Главная идея в том, что универсального лучшего преобразования картинок не может существовать. Вот вы сделали фотку, смотрите на нее глазами и уже сами решаете добавить яркость, выровнять наклон или применить фильтры.
Так же и тут - иногда CLAHE помогает, а иногда портит. Иногда бинаризация делает текст чище, а иногда уничтожает тонкие штрихи. Иногда шарпинг помогает на мыльной фотке, а иногда создаёт лишние артефакты.
Именно поэтому даже при наличии сильной модели вроде PPOCR кастомный препроцессор остаётся важным слоем.
Да, нейросеть хорошо читает текст, когда текст нормально подан. А препроцессор отвечает за то, чтобы реально грязная фотка с телефона стала максимально похожа на аккуратный вход для OCR-модели.
OCR → LLM
Ну что, когда у нас есть распознанный по фото текст задачи, теперь Зада4кин может ее решить?
Да, и я, используя API OpenRouter, отправляю текст с небольшим промтом в GPT-4o mini. На выходе получаем вполне сносное решение.
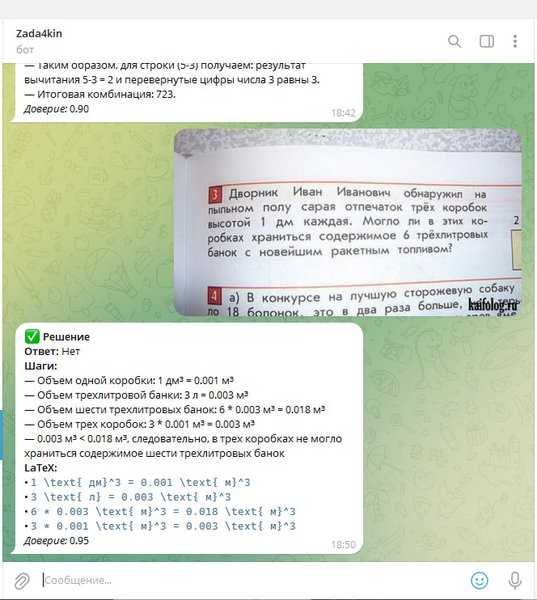
Проблема с формулами
Но увы, сервис пока не увидел мир, т.к., как оказалось (на этапе проектирования я тупо об этом не подумал), что математические задачки имеют много формул и их как-то надо переводить в формат LaTeX - формат (такой формат, который потом поймет LLM).
А если загонять формулы в обычный OCR, он часто теряет структуру: степень, дробь, индекс, корень, скобки. В итоге LLM получает не формулу, а какую-то кашу из текста.
И вот open-source модели для распознавания формул в LaTeX существуют, но на тот момент я не нашёл решения, которое стабильно закрывало бы мой кейс: русская задачка, обычное фото с телефона, текст + формулы, нормальное качество и простая интеграция в продукт.
Есть хорошие проекты и стартапы за рубежом, в т.ч. в США но к ним не подключится: либо приватный доступ, либо платное API + зарубежная/трастовая карта, либо подтверждение юрлица.